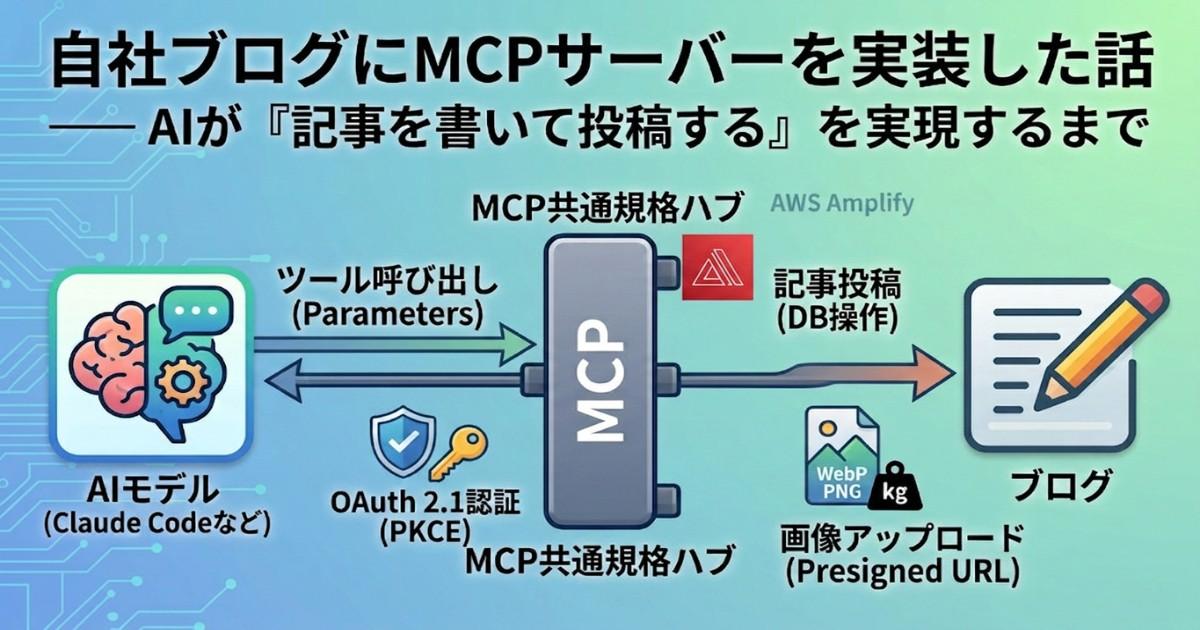
自社ブログにMCPサーバーを実装した話 ── AIが「記事を書いて投稿する」を実現するまで
自社ブログにMCPサーバーを実装した話
UHDの自社HP(このブログ)に、AIから直接記事を投稿できるMCPサーバーを実装しました。stdio?SSE?Streamable HTTP?認証どうする?——AIツール開発で踏んだ地雷と、そこから学んだことを全部書いていきます。
先に結論
この記事、MCPサーバー経由でAIが投稿しています。
Claude CodeやCursorから「ブログ記事を書いて」って指示するだけで、AIがマークダウンを生成して、画像をアップロードして、ブログに投稿してくれる。そんな仕組みを自社ブログに実装しました。
「え、それってただのAPI叩いてるだけじゃないの?」と思うかもしれません。でも実は違うんです。MCPはAIが 自分で判断して ツールを選んで実行する仕組みなんですよね。人間がAPIのエンドポイントを指定するんじゃなくて、AIが「記事を投稿したいからcreate_blog_postツールを使おう」と自分で判断してくれます。
ここが従来のAPI連携と根本的に違うところで、実装してみて初めてその凄さがわかりました。
そもそもMCPって何?
MCPは Model Context Protocol の略で、Anthropicが提唱したオープンプロトコルです。一言で言うと、 AIと外部ツールをつなぐための共通規格 ですね。
例えるなら、USBみたいなものです。USBが登場する前は、プリンターもマウスもキーボードも全部違うコネクタでしたよね。MCPはAIの世界でそれと同じことをやろうとしています。
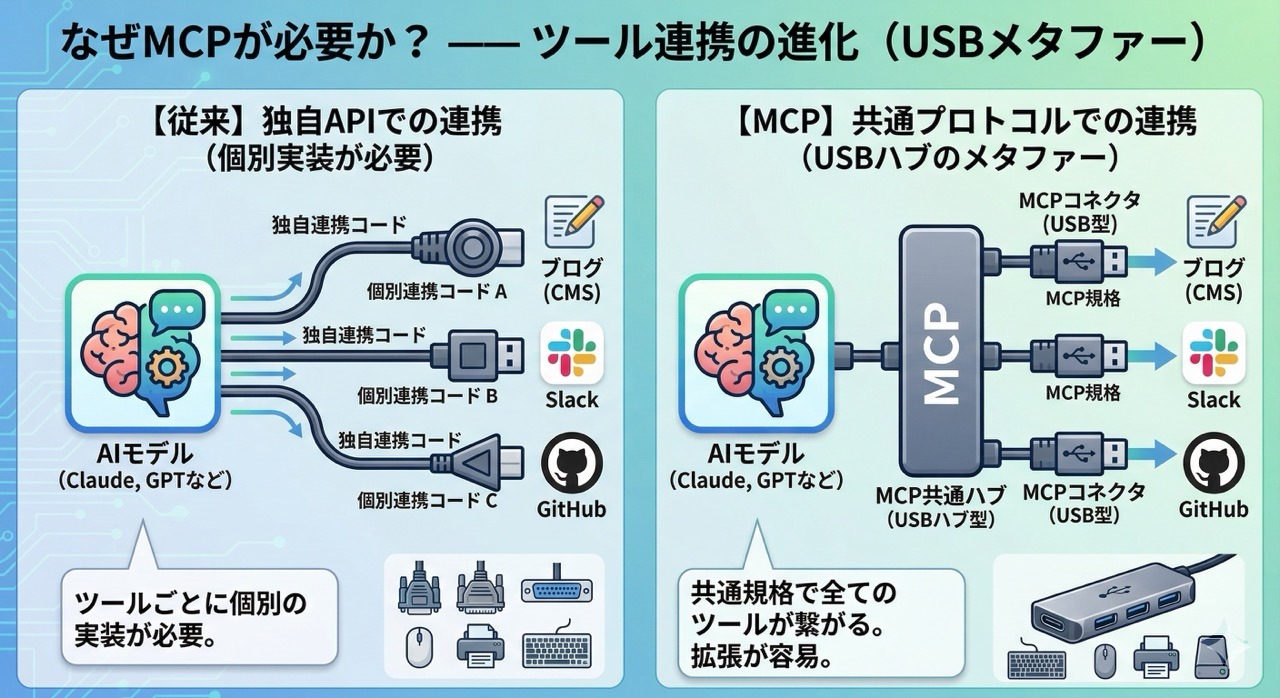
従来は、ブログ、Slack、GitHubなど、ツールごとに独自の連携コードを書く必要がありました。でもMCPがあれば、共通プロトコルで全部つながるようになります。上の図のように、MCPはまさに「USBハブ」のような存在なんです。
AIが「ツールを実行する」とはどういうこと?
ここが一番誤解されやすいポイントだと思います。
AIがツールを実行するって聞くと、AIが直接APIを叩いてるイメージを持つかもしれません。でも実際はこうなっています:
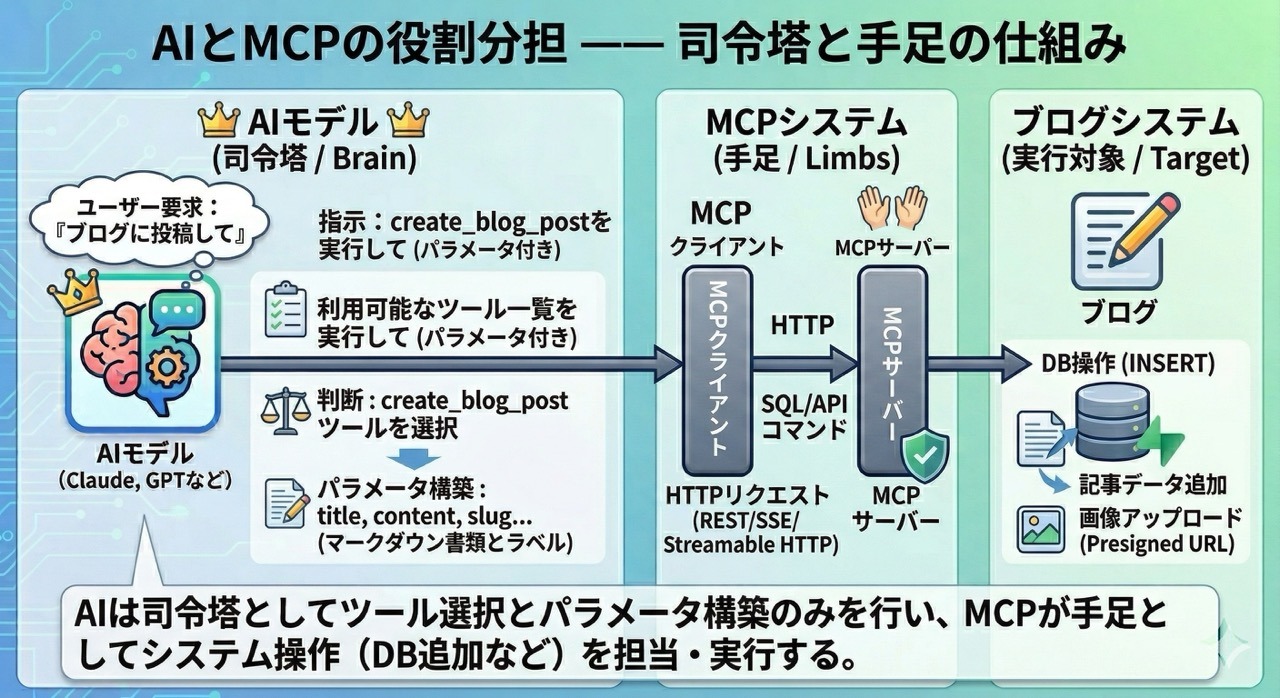
つまり AIは「どのツールを使うか」「どんなパラメータを渡すか」を判断するだけ で、実際の実行はMCPクライアント→MCPサーバーが行ってくれます。AIは司令塔であって、手足はMCPが担当しているんですね。
これが Function Calling (関数呼び出し)の仕組みで、MCPはこのFunction Callingを標準化したプロトコルだと理解するとわかりやすいと思います。
MCPサーバーの3つの構成要素
MCPサーバーは大きく分けて3つの要素で構成されています:
1. ツール(Tools) — AIが実行できるアクション
- create_blog_post:記事を作成する - update_blog_post:記事を更新する - delete_blog_post:記事を削除する - prepare_image_upload:画像アップロード用の署名付きURLを生成する - finalize_image_upload:アップロード済み画像の公開URLを取得する
2. リソース(Resources) — AIが参照できる情報
- blog://posts/list:記事一覧 - blog://posts/read/{slug}:記事の詳細 - blog://taxonomy/categories:カテゴリ一覧
3. プロンプト(Prompts) — 定型の指示テンプレート(今回は未実装)
ツールは「書き込み系」、リソースは「読み取り系」と考えるとわかりやすいです。AIはまずリソースで現状を把握して、ツールで操作を実行するという流れになります。
AIが実行しやすいツール定義のコツ
MCPツールを定義するとき、 AIが正しく使えるかどうか を意識して設計する必要があります。これは人間向けのAPI設計とはちょっと違う観点があるんですよね。
// ❌ AIが迷うツール定義 { name: "post", description: "投稿する", parameters: { data: { type: "string" } // 何を渡せばいいかわからない } } // ✅ AIが正しく使えるツール定義 { name: "create_blog_post", description: "社内CMSに新しいブログ記事を作成する。タイトル、スラッグ、分類タグ、および生のマークダウン本文が必要である。", parameters: { title: { type: "string", description: "投稿の人間が読めるタイトル" }, slug: { type: "string", description: "URLフレンドリーな文字列、小文字、ハイフン区切り" }, content: { type: "string", description: "厳格なマークダウン形式で記述された投稿の本文" } } }
ポイントは3つあります:
- ツール名は動詞+名詞で明確に :
postじゃなくてcreate_blog_postにする - descriptionは具体的に :AIはこの説明文を読んで「いつ使うべきか」を判断します
- パラメータの説明も丁寧に :
slugが何かをAIが理解できるように書いてあげる
実際にこの記事を投稿するとき、僕がAIに「ブログに投稿して」と言うだけで、AIがcreate_blog_postを選んで、タイトルもスラッグもコンテンツも全部自分で組み立てて実行してくれました。 ツール定義がAIにとっての「取扱説明書」 になっているからなんです。
接続タイプの選定:stdio vs SSE vs Streamable HTTP
MCPには3つの接続(トランスポート)タイプがあります。ここの選定で僕はかなり遠回りをしてしまいました。
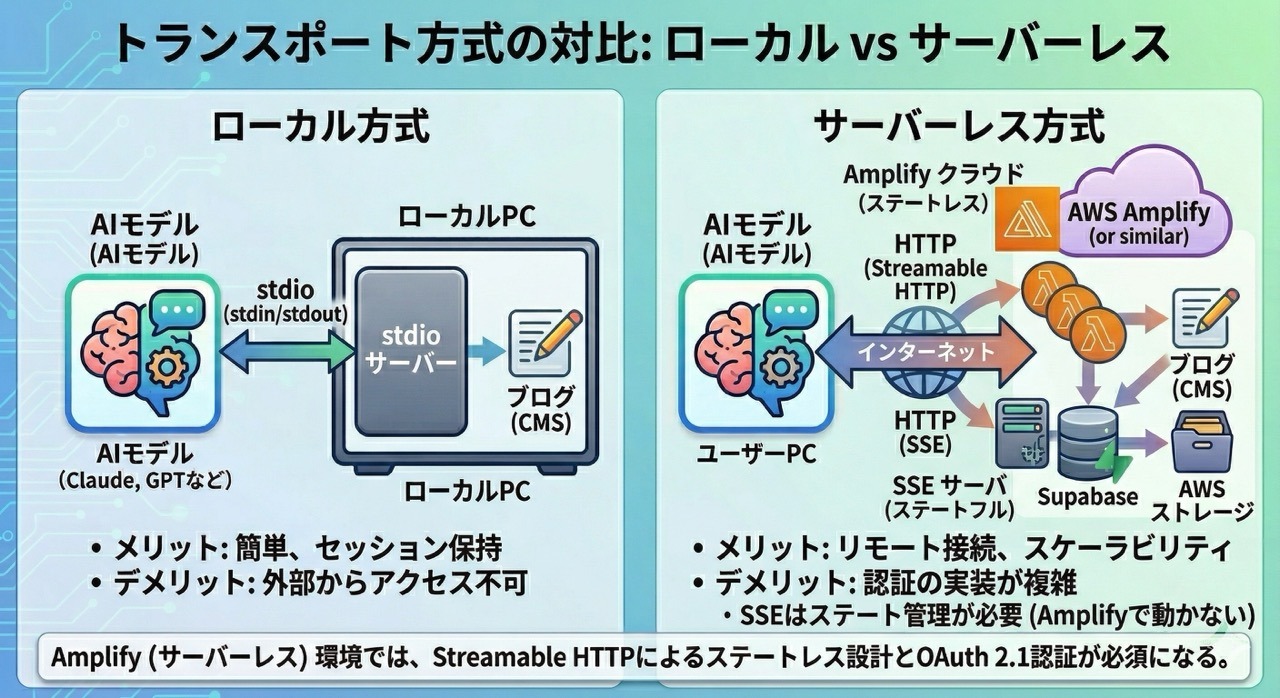
stdio(標準入出力)
MCPクライアント ←(stdin/stdout)→ MCPサーバー(ローカルプロセス)
- MCPサーバーをローカルプロセスとして起動して、標準入出力でやり取りする方式です
- メリット :セットアップがとにかく簡単で、認証も不要。ローカルで完結します
- デメリット :リモートサーバーに接続できません。サーバーはクライアントと同じマシンで動かす必要があります
- 向いてる用途 :ローカルのファイル操作や開発ツール連携
SSE(Server-Sent Events)
MCPクライアント ←(HTTP + SSE)→ MCPサーバー(リモート)
- HTTP経由でリモートのMCPサーバーに接続する方式です
- サーバーからクライアントへの通知にSSE(単方向ストリーミング)を使います
- メリット :リモート接続ができて、認証も実装できます
- デメリット : ステートフル なので、サーバー側でセッションを保持する必要があります
- 向いてる用途 :常駐サーバーでのリアルタイム連携
Streamable HTTP
MCPクライアント ←(HTTP POST/GET)→ MCPサーバー(リモート)
- 最新のMCP仕様で追加されたトランスポートです
- 通常のHTTPリクエスト/レスポンスがベースで、必要に応じてSSEにアップグレードできます
- メリット : ステートレスに対応 していて、サーバーレス環境(AWS Amplify, Vercel)で動きます
- デメリット :比較的新しいので、まだ情報が少ないです
- 向いてる用途 :サーバーレス環境やWebアプリケーション
比較表
| 項目 | stdio | SSE | Streamable HTTP |
|---|---|---|---|
| 接続先 | ローカルのみ | リモート可 | リモート可 |
| ステート管理 | プロセス内 | サーバー側で保持 | ステートレス可 |
| 認証 | 不要 | 実装可能 | 実装可能(OAuth対応) |
| サーバーレス | 非対応 | 非対応 | 対応 |
| セットアップ難易度 | 簡単 | 中程度 | やや高い |
| 現在の対応状況 | 全クライアント対応 | 多くが対応 | 対応拡大中 |
AI開発で踏んだ最初の地雷
ここで正直に告白します。 最初、何も調べずにCursorでAI開発を始めたら、stdioで実装が進んでしまいました。
なぜかというと、CursorやClaude Codeに「MCPサーバーを実装して」と頼むと、AIの学習データに基づいて最もポピュラーな方式——つまりstdioで実装を始めてしまうからです。
でもうちの要件はこうでした:
- Next.jsアプリ(AWS Amplify)にMCPサーバーを組み込みたい → サーバーレス環境
- 外部からアクセスできるようにしたい → リモート接続必須
- 認証が必要 → 誰でも記事を投稿できたら困ります
stdioではこれらの要件を一つも満たせませんでした。
AI系の情報はアップデートが本当に早いです。AIに開発を任せるときこそ、事前調査をちゃんとやる必要があるんだなと痛感しました。
実際、MCPの仕様は2024年11月に公開されてから急速に進化していて、Streamable HTTPが追加されたのは比較的最近のことです。AIの学習データが追いついていないケースは普通にあります。
結局、SSEも検討したんですが、 SSEはステートフルなのでサーバーレス環境(AWS Amplify)では動きません 。Amplifyのサーバーレス関数は1リクエストごとに起動・終了するので、セッションを保持できないんですよね。
ということで、 Streamable HTTP 一択でした。
認証:一番ハマったところ
MCPサーバーの実装で一番難しかったのは、間違いなく認証です。
考えてみてください。MCPサーバーは「AIからブログに記事を投稿できる」ようにするものです。もし認証がなかったら、 誰でもAI経由で勝手に記事を投稿できてしまいます 。
OAuth 2.1 + PKCE
MCPの仕様では、リモート接続時の認証に OAuth 2.1 が推奨されています。しかもセキュリティ強化のために PKCE(Proof Key for Code Exchange) が必須になっています。
PKCEの仕組みを簡単に説明すると、こんな流れです:
1. クライアントがランダムな文字列(code_verifier)を生成する 2. そのハッシュ値(code_challenge)を認可リクエストに含める 3. トークン交換時にcode_verifierを送信する 4. サーバーがハッシュを検証 → 一致すれば本人確認OK
これにより、認可コードが途中で盗まれても、code_verifierを持っていない攻撃者はトークンを取得できなくなっています。
実装した認証フロー
MCPクライアント(Claude Code) │ ├─ 1. /.well-known/mcp.json を取得(ディスカバリ) │ → 認証サーバーのURLを知る │ ├─ 2. /api/oauth/register(動的クライアント登録) │ → client_idを取得する │ ├─ 3. /api/oauth/authorize(認可リクエスト) │ → ブラウザが開いてログイン画面が表示される │ ├─ 4. ユーザーがログイン&同意する │ → 認可コードがコールバックURLに返される │ ├─ 5. /api/oauth/token(トークン交換) │ → PKCE検証 → JWTアクセストークンが発行される │ └─ 6. /mcp(MCPエンドポイント) → Authorizationヘッダーにトークンを付けてリクエストする → サーバーがJWTを検証 → ツールが実行される
特に ディスカバリ(/.well-known/) の実装がめちゃくちゃ面倒でした。RFC 8414、RFC 9728に準拠する必要があって、以下のエンドポイントを全部用意しなきゃいけなかったんです:
/.well-known/mcp.json— MCPサーバーのメタデータ/.well-known/oauth-protected-resource— 保護リソースの場所/.well-known/oauth-authorization-server— 認可サーバーのメタデータ
これらが一つでも欠けていたり、レスポンスの形式が微妙に違うだけで、クライアント側が認証フローを開始できなくなります。
JWTトークンの設計
認証が通ったら、JWTトークンを発行します。このトークンにユーザー情報を含めることで、 「誰が投稿したか」をMCPサーバー側で判別 できるようにしています。
{ "sub": "user-id-here", "client_id": "mcp-client-id", "role": "authenticated", "iss": "https://admin.uhd-inc.jp/oauth", "exp": 1234567890 }
これによって以下のことが実現できています:
- 自分の記事しか編集・削除できない (Confused Deputy対策)
- 投稿者の情報が自動で紐づく
- 1時間で期限切れになる (トークン漏洩時のリスク軽減)
サーバーレス対応:ステートレス設計のポイント
AWS Amplify(Next.js)で動かすために、MCPサーバーは完全にステートレスに設計しました。
// リクエストごとに新しいサーバーインスタンスを生成 export async function POST(request: NextRequest) { const server = createMcpServer(); // 毎回新規作成 const transport = new WebStandardStreamableHTTPServerTransport({ sessionIdGenerator: undefined, // セッションIDなし = ステートレス }); // ... }
ポイントはsessionIdGenerator: undefinedです 。これを設定することで、サーバーはセッションを保持せず、毎リクエスト独立して処理されるようになります。AWS Amplifyのサーバーレス関数と完璧に相性が良いんですよね。
画像アップロードの工夫
ブログ記事には画像が必要ですが、サーバーレス環境にはファイルシステムがありません。そこで 署名付きURL(Presigned URL) パターンを使いました。
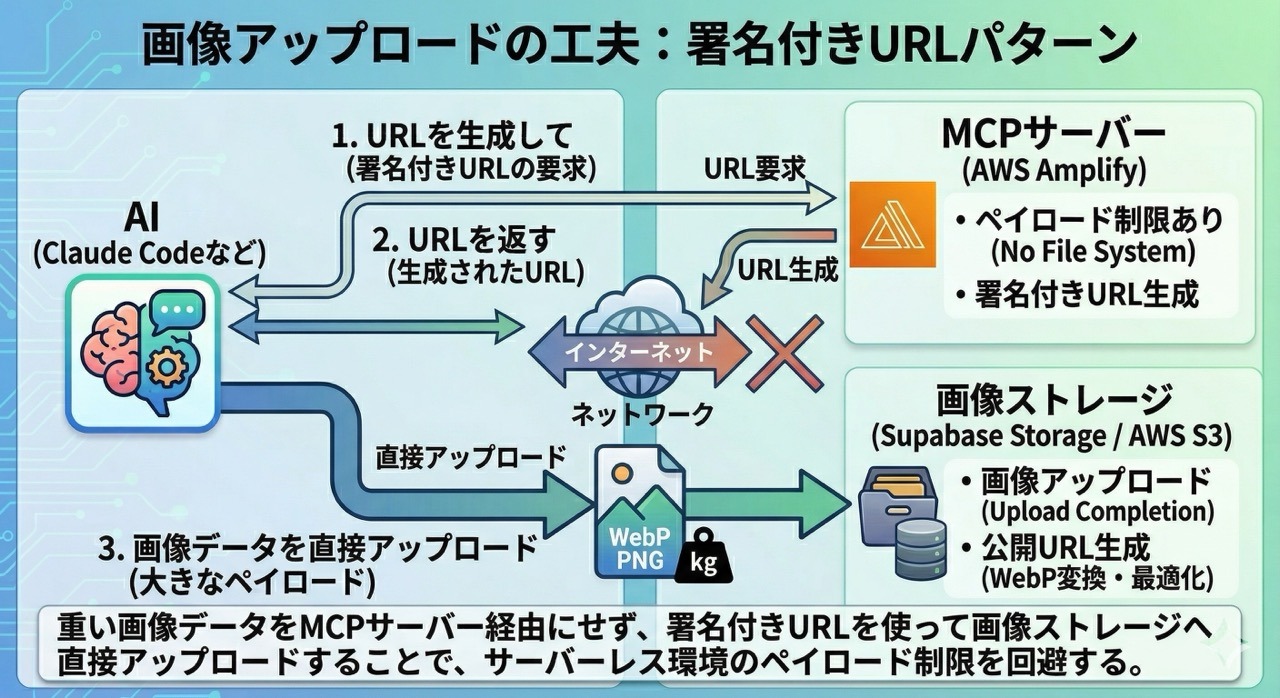
この図のように、MCPサーバーが署名付きURLを生成して、AIクライアントが画像ストレージに直接アップロードする仕組みになっています。MCPサーバーは画像データを一切扱わないので、AWS Amplifyのペイロード制限にも引っかかりません。
流れとしてはこうです:
1. AI:「画像をアップロードしたい」 2. MCPサーバー:署名付きURLを生成して返す 3. AI:署名付きURLに直接アップロード(MCPサーバーを経由しない) 4. AI:「アップロード完了。公開URLをください」 5. MCPサーバー:公開URLとWebP変換済みURLを返す
この方式のおかげで、重い画像データがMCPサーバーを通らずに済むようになっています。
実装の全体像
最終的な構成はこうなりました:
Claude Code / Cursor │ │ Streamable HTTP + OAuth 2.1 │ ▼ Next.js App Router(AWS Amplify) ├── /mcp → MCPエンドポイント(POST/GET) ├── /.well-known/mcp.json → ディスカバリ ├── /.well-known/oauth-* → OAuth ディスカバリ ├── /api/oauth/register → 動的クライアント登録 ├── /api/oauth/authorize → 認可 ├── /api/oauth/token → トークン交換 └── /oauth/authorize → 同意画面UI │ ▼ Supabase ├── blog_posts テーブル → 記事データ ├── blog_categories テーブル → カテゴリ ├── mcp_oauth_states テーブル → OAuth状態管理 ├── mcp_oauth_codes テーブル → 認可コード(PKCE付き) └── Storage(blog-images) → 画像ストレージ
使用した主要ライブラリ
| ライブラリ | 用途 |
|---|---|
@modelcontextprotocol/sdk | MCPサーバー実装の公式SDK |
jose | JWT署名・検証 |
zod | ツールパラメータのバリデーション |
gray-matter | マークダウンのフロントマター解析 |
開発中にハマったポイント
| # | ハマりポイント | 原因 | 解決策 |
|---|---|---|---|
| 1 | AIがstdioで実装を始めてしまう | AIの学習データが古かった | 事前に仕様を調査してプロンプトで明示した |
| 2 | SSEがAWS Amplifyで動かない | サーバーレスはステートフル不可だった | Streamable HTTPに切り替えた |
| 3 | OAuthディスカバリが通らない | RFC準拠の微妙なフォーマット差異があった | 仕様書を読みながら一つずつ修正した |
| 4 | PKCE検証が失敗する | code_challengeの生成方法が不一致だった | S256メソッドの実装を厳密に修正した |
| 5 | 画像アップロードがタイムアウトする | サーバー経由でファイルを送っていた | 署名付きURLでダイレクトアップロードに変更した |
| 6 | JWTの検証が通らない | Supabase JWT SecretとMCPで異なるキーを使っていた | SUPABASE_JWT_SECRETに統一した |
特にハマったのが #3のOAuthディスカバリ です。MCPクライアント(Claude CodeやCursor)は、サーバーに接続するとき最初に/.well-known/のエンドポイントを叩いて認証情報を取得します。ここのレスポンス形式が仕様と微妙に違うだけで、クライアントが「認証できません」とエラーを出してしまうんですよね。しかもエラーメッセージが不親切で、何が間違っているのかわからない。
結局、MCPの仕様書とRFC 8414を横に置いて、フィールドを一つずつ検証していきました。
学んだこと・伝えたいこと
1. AI開発でも「事前調査」は絶対に必要
AIに実装を任せると、AIの学習データに基づいた「古い正解」で進んでしまうことがあります。特にMCPみたいな新しいプロトコルは仕様の更新が早いので、 最新の公式ドキュメントを自分で読んでからAIに指示を出す のが本当に大事です。
「AIに聞けばわかる」は半分正解で半分危険だと思います。AIは知らないことを「知らない」と言わずに、もっともらしい古い情報を返してくることがあるんですよね。
2. 認証は最初に設計するべき
MCPサーバーの機能実装自体はそこまで難しくありません。ツールを定義して、Supabaseにクエリを投げるだけです。 全体の工数の6割は認証でした 。
OAuth 2.1、PKCE、JWT、ディスカバリエンドポイント、動的クライアント登録——これらを全部正しく実装しないと、MCPクライアントから接続すらできません。
もしMCPサーバーを実装するなら、 認証から先に取り組む ことを強くおすすめします。
3. MCPは「AIネイティブなAPI」だと感じた
MCPを実装して一番感じたのは、これは単なるAPIの上位互換ではなく、 AIのために設計されたインターフェース だということです。
- ツールの
descriptionはAIが読んで判断するためのもの - リソースはAIがコンテキストを理解するためのもの
- パラメータの型と説明はAIが正しく値を組み立てるためのもの
人間向けのAPIドキュメントとは違い、 MCPのツール定義はAIに対する「取扱説明書」 として機能しています。ここの設計をサボると、AIが間違ったツールを使ったり、パラメータを間違えたりしてしまいます。
4. 「MCPで何ができるか」の可能性は広い
今回はブログの投稿に使いましたが、MCPの可能性はもっと広がっていくと思います:
- 社内ナレッジベース にAIから直接アクセスできるようにする
- プロジェクト管理ツール のタスクをAIに作成・更新してもらう
- 顧客管理システム のデータをAIに参照・更新してもらう
- 監視システム のアラートをAIに確認・対応してもらう
要するに、 社内の全システムにAIの「手と目」を与える ことができるんです。MCPはそのための共通プロトコルになっていくと思います。
まとめ
やったことを振り返ると、こんな流れでした:
「ブログにMCPサーバーを実装したい」 ↓ 接続タイプの選定(stdio → SSE → Streamable HTTP) ↓ OAuth 2.1 + PKCE認証の実装(ここが一番大変だった) ↓ MCPツール・リソースの定義 ↓ サーバーレス対応(ステートレス設計) ↓ 画像アップロード(署名付きURL) ↓ 完成 → この記事をMCP経由で投稿
MCPはAIと外部システムをつなぐ共通規格であり、これからのAI開発では避けて通れない技術になっていくと感じています。
特別な技術スタックは使っていません。Next.js + Supabase + MCPの公式SDKだけです。ただし、認証周りは甘く見ないほうがいいです。OAuth 2.1の実装は想像以上に手間がかかります。 でもそこを乗り越えれば、AIに「手と目」を与えるインフラが手に入ります。
#MCP #ClaudeCode #AIエージェント #Next.js #OAuth #AWSAmplify #UHD
